



Include CSS or JS first in your HTML page for best performance?
I was recently having a discussion with Rich Harris about performance optimizations for CSS and JS handling. A few questions came up for which I didn’t have a good answer. One of those is whether the old advice that you should include and load CSS first in your HTML page for best performance was still true today. The best answer I found was a StackOverflow thread from 2012 where folks who really knew this stuff like Jeff Atwood and Steve Souders were participating. It turns out that even in 2012 that was pretty old advice as Josh Dague provided some detailed information and benchmarking, which suggested it was better to put JS first on desktop and CSS first on mobile.
At the time speculative parsing was still very new and it appeared that even the newest version of WebKit for Android did not appear to support it. I was skeptical that WebKit hadn’t advanced in the eight years since then, so decided to test for myself. The easiest site I had access to test on was c3.ventures, which includes jQuery and Bootstrap JavaScript as well as Bootstrap and webfonts CSS, so it seemed like a reasonable test.
The first thing I wanted to test was whether the assets could be downloaded in parallel on mobile or the blocking behavior from 2012 was still present. I took some time to figure out how to connect the Android debugger to Chrome mobile, and it turns out that things had changed!
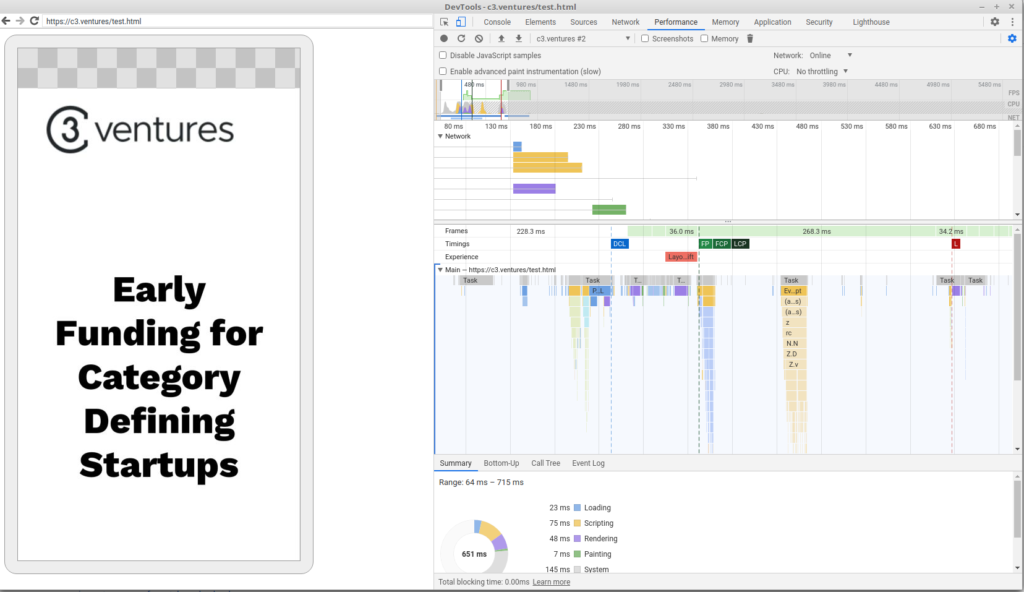
(yellow and purple bars on top)
The next step was to time the page render over several runs.
| CSS First | JS First | |
| Mean | 280.1 | 277.8 ms |
| Standard Deviation | 21.9 ms | 56.8 ms |
It turns out it really doesn’t make much of a difference, at least in this case. The page layout is fairly simple and perhaps I’d have gotten a different answer on a more complex page. But as of right now, I can’t say that one is better than the other in any statistically significant way. It’s probably a much better idea to focus your efforts on more significant changes.